
AMD这场AI浓度爆表的发布:各“U”上阵、性能硬核对标,但掌舵10年的苏妈说:“一切刚开始”
这一天是美西时间10月10日,位于旧金山的Moscone Center从清晨起就人头涌动,大家都在坐等这场发布。
随后,AMD 董事会主席及首席执行官 Lisa Su博士登台,她的开场开门见山:
· “高性能计算是现代世界的基本组成部分,AMD在推进AI的过程中,也推动了对更多计算的需求。AMD真正致力于推动高性能计算和AI基础设施的开放式创新。”
· 以及Lisa Su博士接下来一句打趣的话:“我们今天会聊很多AI的内容,如果大家没意见的话。”
话音落下,既为今天的这场活动,也为今年的她掌舵AMD第十周年,定下一个主基调。

在持续两小时密集的发布里,Lisa Su博士一一亮出核心产品升级,重点包括四款新品:第五代EPYC服务器“Turin”、AI加速器“Instinct MI325X” 、面向AI PC的处理器“Ryzen AI 300 PRO”、以及第三代DPU Pensando系列,用一张完整的CPU、GPU、DPU版图,强化从数据中心、到PC市场、到边缘计算的疆土,形成了某种意义上的“狼群效应”。

要知道,今天当我们热议AI,不再只是在谈技术,可能是在谈关于“如何加速拥抱AI”,关于“如何最大化释放AI价值”,以及关于“如何为正确的应用选择正确的计算”,这些话题,或许没有放之四海皆准的答案,而AMD对此分享了核心策略。
Lisa Su博士直言,对于AMD来说,AI平台有四个关键:1、一个用于训练和推理的最强计算引擎;2、一个开放的、经过验证的、对开发者友好的软件平台;3、一个共同创新的AI合作伙伴系统;4、在集群水平上的系统设计。

与这一雄心相匹配的,就是接下来出场的王牌产品了。
第一张王牌:EPYC升级,CPU也可以是AI的好搭子
CPU,是AMD多年来持续攻城略地的领域。
回顾过去的7年,自2017年重回数据中心市场后,AMD一路打开局面:随着第一代Naples EPYC 7001系列、第二代Rome EPYC 7002系列、第三代Milan EPYC 7003系列、第四代Genoa EPYC的到来,AMD在数据中心的CPU市场份额从2018年还只有2%、2020年达到8%、2022年达到27%,到今年上半年已攀升至34%。强势程度可见一斑。
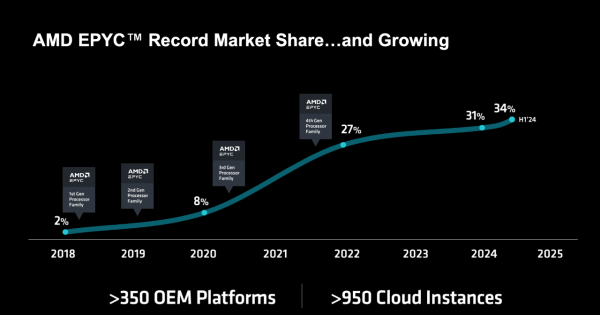
所以当“34%”这个数字出现时,现场响起了一阵掌声,EPYC被Lisa Su博士称为是“现代数据中心的首选CPU”,目前已在全球覆盖超过350个OEM平台和超过950个云实例。
紧接着,AMD正式官宣第五代EPYC新品:EPYC 9005系列,代号“Turin”!

第五代EPYC提供两种不同的核心配置:一个是基于Zen 5架构,拥有128核、256线程,采用4nm;另一个是基于Zen 5c架构,拥有192核、384线程,采用3nm。

性能方面,该处理器在计算、内存、IO平台连接、安全四个层面做了全面升级。

具体而言,“Zen 5”为EPYC 9005系列带来了在云、企业工作负载中的IPC提升17%,以及在AI、HPC应用中的IPC提升37%。

市场经常拿AMD EPYC与英特尔至强芯片做对比,而AMD则直接在现场用一系列参数对其“贴脸开大”。比如,在行业标准的SPEC CPU 2017基准测试中,192核EPYC 9965对比英特尔64核至强8592+提升2.7倍,其他对比参数如下图。

没有对比就没有伤害,由于性能上更强劲,也带来了应用上的更佳表现。比如在视频转码、图像渲染、商业App、数据库等如下图中的8个用例,EPYC 9965都扛的住对比。
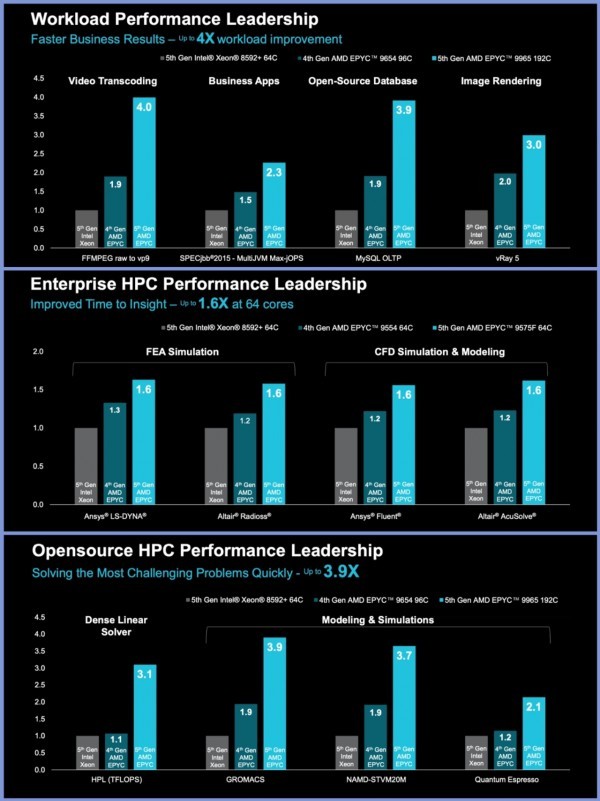
甚至,Lisa Su博士在这里给CIO等技术负责人算了笔账:那些4年未更新的数据中心,如果从二代至强铂金8280升级到EPYC 9665,只需131台服务器就能达到原来1000台的性能水平,从而节省87%的占地空间、降低最多68%功耗、三年TCO成本节省最多67%,再加上企业软件许可成本,这意味着企业可在6-12个月内实现投资收支平衡。

此外,AMD还提供了一套完整的软件生态系统,实属面面俱到了。

而针对客户现在流行用“CPU+GPU组成超高性能的AI计算系统”的这种混搭做法,EPYC也是最佳搭档。因为不管你用的是AMD的Instinct MI300X系列,还是友商的H100系列,EPYC都可以放大GPU的能力。
比如搭配MI300X GPU,相比至强8592+,EPYC 9575F可将GPU系统的推理性能、训练性能分别提升8%、20%;同样是搭配英伟达H100,EPYC 9575F可将GPU系统的推理性能、训练性能相比至强8592+分别提升20%、15%。

并且AMD连量身定制的混搭方案也奉上了,以下两张图分别是:适配Instinct系列GPU的EPYC AI主机CPU型号,以及适配英伟达GPU的EPYC AI主机CPU型号。


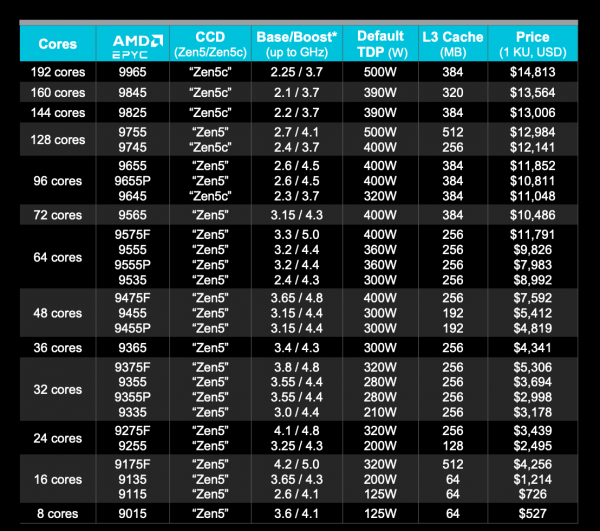
价格方面,EPYC 9005全系列一共多达27款,包括22款Zen 5、5款Zen 5c,其中的“顶配”EPYC 9965,采用192核、384线程、384MB三级缓存,主频2.25-3.7GHz,热设计功耗500W,价格为14813美元(约合10万元人民币)。
第二张王牌:GPU界的诚意之作,Instinct MI325X不惧比较
要说英伟达在AI芯片领域占据强势地位,那么放眼望去,AMD或许是为数不多能在模型训练,推理等场景提供全链条对标技术的公司之一。
目前分析师的共识是,AMD预计将在未来几年夺食AI加速器市场约5%至7%的份额,而美国银行证券分析师Vivek Arya直指,如果到2026年底,AMD的份额能达到 10%,那么该公司的销售额将增加约50亿美元。
而作为AMD的AI加速器扛把子Instinct,此前也公布了直至2026年的最新路线图,卷出了“年更”节奏:2024年Q4将带来Instinct MI325X;2025年,采用CDNA 4架构的Instinct MI350系列将会问世,搭载3nm工艺;2026年,CDNA“Next”架构将登场,用于Instinct MI400系列。

照此节奏,AMD这次就正式推出新一代AI加速器“选手”——Instinct MI325X。

Instinct MI325X采用CDNA 3 GPU架构,由于配备了速度更快、密度更高的HBM3E内存,比上一代产品实现了内存带宽提升到6TB/s、容量提升到256GB。另外,它在FP8和FP16精度下分别达到2.6 PF和1.3 PF的峰值理论性能。

由8张MI325X集成的GPU平台有2TB HBM3E内存,FP8精度下的理论峰值性能达到20.8 PF,FP16精度下达到10.4 PF。系统配备 AMD Infinity Fabric 互连技术,带宽高达896 GB/s,总内存带宽达到了 48 TB/s。

从推理性能来看,相比英伟达H200 HGX,无论单卡还是8卡平台,MI325X服务器平台在跑不同的大模型时,推理性能领先20%-40%。
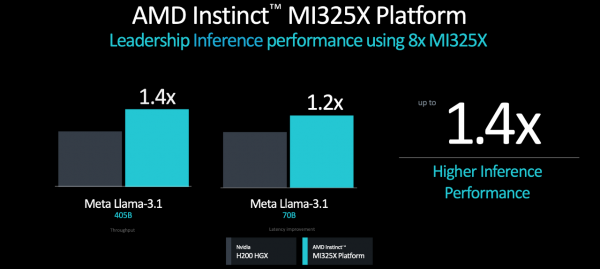
从训练性能来看,单张MI325X训练Llama 2 7B的速度超过单张H200。而8张MI325X训练Llama 2 70B的性能,基本与H200 HGX持平。

MI325X将于2024年第四季度开始投产,而合作伙伴的整机系统、基础架构解决方案,将从2025年第一季度起陆续推出。
不过到那时,隔壁友商将大规模量产某芯片,所以不知是否嗅到危机,这次除了MI325X之外,AMD还预告了它的继任者MI350系列。
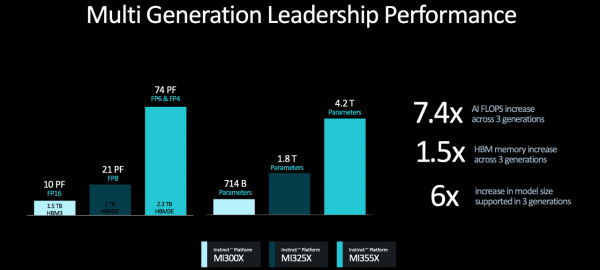
MI350系列采用CDNA 4 架构,3nm工艺,配备高达288GB的HBM3E高带宽内存,它的一个重要更新是新增对FP4/FP6数据类型的支持,推理性能相比基于CDNA 3的加速器有高达35倍的提升,有望在2025年下半年上市。

相比MI325X,MI355X的FP8和FP16性能提升了80%,FP16峰值性能达到2.3PFLOPS,FP8峰值性能达到4.6PFLOPS,FP6和FP4峰值性能达到9.2PFLOPS。

而相比8卡MI300X,8卡MI355X的AI峰值算力提升多达7.4倍、HBM内存提高1.5倍、支持的模型参数量提升了6倍。
当然我们都知道,要打造一款成功的AI加速器,一定少不了的关键三要素是:硬件、软件、生态系统。
软件方面,AMD ROCm开发平台是一套完整的AI软件栈,从底层的“硬件”,到中间的“开发工具”,再到上层的“AI模型与算法”,丰富程度堪称百宝箱。

关键的是,ROCm还在持续进化。不但支持几乎所有的AI框架与模型,还在不断优化对GenAI的支持,惠及开发者。

生态方面,AMD的策略分两步走,一方面对外在不断壮大Instinct的“朋友圈”,比如微软、OpenAI、Meta都在越来越多的选择Instinct;再比如,AMD加强了与Hugging Face和Meta的合作,对于超过100万种主流模型都能做到开箱即用。

在现场播放的视频片段中,AMD 董事会主席及首席执行官 Lisa Su博士对话微软CEO萨提亚·纳德拉,萨提亚分享说道:为企业带来成本效益,是目前AI开发最重要的指标。他同时提到:
“过去四年来,微软一直在利用AMD的AI创新来支持自己的云创新,这对两家公司来说都是一个非常有益的反馈循环,并且会带来回报。”

另一方面,除了对外培养生态伙伴,AMD对内也在通过一系列并购,扩大自身的AI商业版图。其中仅过去几个月就完成了两笔收购:
7月份,AMD以6.65亿美元的价格,完成了对欧洲最大的私人AI实验室Silo AI的收购,获得了端到端AI解决方案、约300名AI专家,势必会增强在欧洲的AI业务实力;8月份,AMD又以49亿美元并购AI系统企业ZT Systems,ZT Systems专门设计、集成、制造、部署AI系统,也是Open AI的系统供应商,这项并购案有望强化AMD在数据中心的AI基础架构,如系统设计、集成能力。

第三张王牌:无网络不计算的DPU
可以肯定地说,在实现AI最佳性能的过程中,网络是根基。
“糟糕的网络可能会给AI集群造成重大瓶颈。”AMD高级副总裁、数据中心嵌入式解决方案事业部总经理Forrest Norrod指出,AI模型平均有30%的训练周期时间都花在网络等待上。在训练和分布式推理模型中,通信占了40%-75%的时间。

AI网络可以分为「前端」和「后端」:「前端」向AI集群提供数据和信息,可编程DPU从而不断发展;「后端」管理加速器与集群间的数据传输,可获得最大利用率。
为了有效管理这两个网络,并推动整个系统的性能、可扩展性和效率提升,AMD这次发布了两款新品:用于前端网络的Pensando Salina 400 DPU、用于后端网络的Pensando Pollara 400网卡。


其中,Salina 400是AMD第三代可编程DPU,支持400G吞吐量,可实现快速数据传输速率,可为数据驱动的AI应用优化性能、效率、安全性和可扩展性。
而Pollara 400则采用AMD P4可编程引擎,支持下一代RDMA软件,并以开放的网络生态系统为后盾,对于在后端网络中提供加速器到加速器通信的领先性能、可扩展性和效率至关重要。
第四张王牌:AI PC时刻的杀手锏,专攻企业级需求
AI让PC市场焕发新生的故事,不只发生在消费级市场,同时也在企业级市场上演,或是提质提效,或是激发创造。
而在最早一批带动AI PC活力的先锋队伍里,AMD是其中不容小觑的一员,毕竟这家巨头有着“全球首家在x86处理器中集成NPU AI独立引擎”的风光伟绩。
继今年6月份推出第三代AI PC处理器锐龙AI 300系列处理器(代号Strix Point)之后,AMD这次又正式官宣新成员——锐龙AI PRO 300系列,这已经是AMD面向商用AI PC的第三代产品。

梳理历代产品,2023年6月,AMD通过锐龙PRO 7040系列首次叩开商用AI PC的大门,NPU算力达到10 TOPS;2024年4月,锐龙PRO 8040系列亮相,NPU算力提高到16 TOPS。

如今,锐龙AI PRO 300系列的算力最高可达到55TOPS,完全满足Copilot+PC的条件,支持包括电话会议实时字幕、语言翻译、AI图像生成等功能。所以AMD称,该系列处理器是首款专为企业Copilot+PC而设计的芯片。

此次锐龙AI PRO 300的首发阵容有三个型号,分别是:锐龙AI 9 HX PRO 375、锐龙AI 9 HX PRO 370、锐龙AI 7 PRO 360。

性能方面概括而言,锐龙AI PRO 300系列基于4nm,主要有四项更新:CPU部分采用Zen 5架构(最多12核、24个线程),NPU采用了XDNA 2架构,GPU采用了RDNA 3.5架构(最多16个计算单元),以及针对企业加入了AMD PRO安全技术。
其中关于安全的AMD PRO技术,通过多层软件和硬件级防护避免商用客户受到威胁;而AMD AI PRO技术则通过AI来加强安全,反钓鱼主动防御先进威胁;另外AI增强的威胁检测系统,也能提升网络安全性,在像医疗和金融等领域按照相应标准实现更好的防控。AMD预计到明年,将会有超过100款商用AI PC平台采用锐龙AI PRO技术。



续航方面,由于4nm制程工艺,搭载该处理器的AI PC续航可达23小时;连续使用Microsoft Team,续航超过9小时。
不难看出,AMD对于这颗芯是寄予了厚望,正如Lisa Su博士所说:“锐龙AI PRO 300是为了提供最佳性能、长续航、安全性、可靠性、以及企业所需的一切而构建的。”
以上不难看出,这一次,AMD是做足了准备而来。
印象中现场还有这样一幕,在大会接近尾声,Lisa Su博士登台致谢,其中提到了所有到场为AMD站台的合作伙伴,Google、甲骨文、微软、Meta、Dell、HPE、Databricks等等,给这场有些“火药味”的发布画上了一个还算融洽的句号。
如同开篇所提,今年是Lisa Su博士掌舵AMD的十周年,在这一过程中,Lisa Su博士带领AMD公司从一个充满挑战的位置,逐渐突出重围成为AI赛场的一匹黑马。
某种意义上,这或许就像她在个人社交平台上所写的一样:
“尽管过去十年令人惊叹,但最好的还在后头。”

来源:至顶网
